






Purchased lead lists decay fast because people change jobs, companies rebrand, and emails bounce long before your team gets to them. Web scraping fixes this by pulling contact and company data directly from live sources, so your prospect lists reflect what is out there right now.
This article covers how web scraping for lead generation works, where to pull data from, how to turn raw data into qualified prospects, and what your team needs to know about staying compliant.
Key Takeaways
- Web scraping pulls contact and company data from live sources, so your prospect lists reflect current information rather than what a vendor compiled months ago
- The highest-value scraping sources for B2B teams are business directories, job boards, company websites, and industry-specific listing sites
- Raw scraped data needs cleaning and enrichment before it is useful for outreach. The scraping itself is the easy part
- B2B web scraping is legal in many jurisdictions when done correctly, but GDPR and CCPA compliance are not optional and need to be built into your process from the start
- A purpose-built scraping tool that delivers clean, export-ready data removes most of the technical burden from your team
What Is Web Scraping for Lead Generation
Web scraping is the automated extraction of publicly available data from websites. Instead of someone on your team manually visiting pages and copying information, a scraper moves through a defined set of sources and pulls the data you need in a fraction of the time.
In a lead generation context, that data typically includes:
- Business names and contact details
- Job titles and work email addresses
- Company size, industry, and location
- Phone numbers and website URLs
The difference between scraping and buying a list comes down to freshness. A scrape pulls from live pages, so the data reflects what is published right now. A purchased list starts decaying the moment it is compiled, and by the time your team loads it into the CRM, a portion of those contacts have already changed jobs, switched emails, or gone dark.
It also gives your team a level of specificity that purchased lists rarely offer. You can target businesses in a particular city, a specific industry, a certain company size range, or companies that posted a particular type of job in the last 30 days.
One thing to know upfront is that web scraping is not a shortcut to a ready-to-use prospect list. Raw scraped data needs cleaning, deduplication, and enrichment before your team runs outreach from it. That step is where a lot of teams underestimate the work involved.
Where Web Scraping Pulls Lead Data From
The quality of your scraped lead list depends almost entirely on where you pull data from. Different sources serve different targeting needs, and knowing which one fits your ICP saves your team a lot of cleanup work later.
Business Directories and Listing Sites
Google Maps, Yelp, and industry-specific directories are among the highest-ROI sources for local and SMB targeting. The data is structured, publicly available, and tends to be more current than what you find in purchased databases because businesses update their own listings regularly.
If you are targeting HVAC contractors in Texas, law firms in Chicago, or dental practices in New York, a directory scrape gets you business names, phone numbers, websites, and location data fast. Each listing typically includes emails, phone numbers, and social profiles, giving your team enough to start qualifying prospects before enrichment even begins.
Job Boards and Career Pages
Job postings are one of the more reliable buying signal sources available to B2B teams. A company hiring a VP of Sales is likely evaluating new tools. A business expanding its engineering team may need infrastructure or security solutions.
Scraping job boards lets your team get in front of the right companies at the right time. Pair that data with a solid follow-up automation system, and nothing falls through the cracks. The signals worth watching include:
- Leadership hires signaling strategic shifts
- Volume hiring in a specific department indicating growth
- Tech stack mentions in job descriptions revealing what tools a company already uses
Company Websites and Contact Pages
Company websites are the most direct source of accurate contact data. Emails, phone numbers, and team information pulled from a company's own pages tend to be more reliable than third-party aggregators, simply because the company controls and updates that information themselves.
Social and Professional Platforms
LinkedIn is the obvious source for B2B contact data, but it explicitly prohibits scraping in its terms of service. That said, a US court ruling in the hiQ vs LinkedIn case confirmed that scraping publicly available LinkedIn profiles does not automatically violate the Computer Fraud and Abuse Act.
For B2B teams, the safest approach is:
- Limit scraping to publicly visible profile data only
- Never scrape behind a login wall
- Apply GDPR opt-out mechanisms if you are targeting EU-based contacts
- Use scraped LinkedIn data for internal lead generation purposes only, not resale
What Web Scraping for Lead Generation Looks Like in Practice
The easiest way to understand how this works is to walk through a real example.
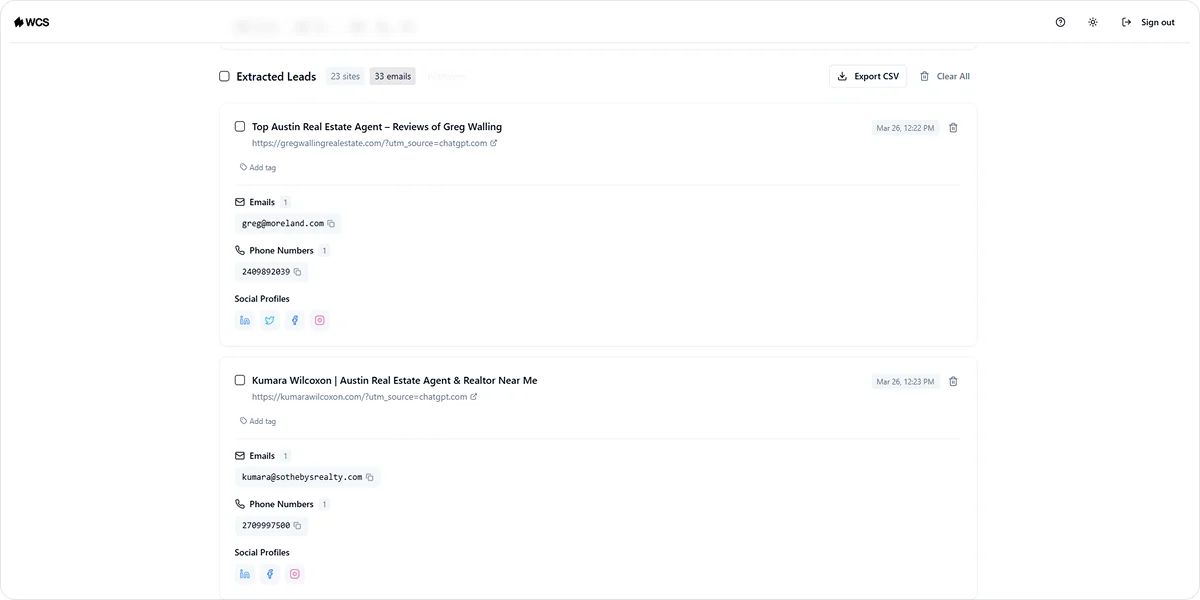
A B2B team targeting HVAC contractors in California runs a scrape of Google Maps. The scraper pulls business names, phone numbers, websites, and locations across the state in minutes. That data gets filtered by location and company size, enriched with verified email addresses, and exported as a clean CSV that goes straight into the CRM.
No manual research. No paying for a list that was built six months ago. Just a targeted, current prospect list built around a specific ICP.
We Capture Sales's Market Miner works this way. It scrapes competitor activity and contact data filtered by industry and location, and delivers clean CSV exports your team can act on without spending time on manual cleanup.
How to Turn Scraped Data Into Qualified Leads
Scraping gets you the raw material, but a raw list rarely converts on its own. Before your team runs a single outreach sequence, three steps turn that data into a list your team can confidently work from:
Clean and Deduplicate the Data
Raw scraped data almost always has issues. Duplicate records, inconsistent formatting, missing fields, and invalid email formats are common. Running a cleaning pass before anything else saves your team from bounced emails and wasted outreach effort down the line.
A few things to check before your list goes anywhere:
- Remove duplicate records across the same contact or company
- Standardize formatting across name, email, and phone fields
- Flag and remove email addresses that fail basic format validation
- Fill obvious gaps in the company or location fields where data is missing
Enrich Your Scraped Contacts Before You Reach Out
A name and email address alone is not enough to qualify a prospect. Enrichment adds the context your team needs to prioritize outreach: company size, industry, location, revenue range, and tech stack. A contact at a 10-person startup and a contact at a 200-person mid-market company may both be on your scraped list, but they are not the same conversation.
The goal is to know enough about each contact to decide whether they fit your ICP before anyone on your team spends time on them.
Score and Prioritize Before You Outreach
Not every contact on a scraped list deserves the same priority. Before your team starts sending, apply basic scoring criteria tied to your ICP. Company size, industry fit, job title, and any behavioral signals you have will tell you which contacts to lead with and which to deprioritize.
This step is what separates a list that converts from one that burns your domain reputation. It is also where AI sales automation picks up, turning a prioritized list into a sequenced, adaptive outreach workflow.
Web Scraping Compliance: What B2B Teams Need to Know
Web scraping is legal in many jurisdictions, but that does not mean anything goes. The data you collect, how you use it, and who it belongs to all carry legal implications your team needs to understand before running any scraping campaign.
The key frameworks to know:
- CFAA (Computer Fraud and Abuse Act): The hiQ vs LinkedIn case confirmed that scraping publicly available data does not automatically violate the CFAA. That ruling applies to public-facing pages. Scraping behind a login wall is a different matter entirely.
- GDPR: If any of your scraped contacts are based in the EU, GDPR applies. For B2B outreach, legitimate interest is the most commonly used lawful basis, but it requires a documented balancing test, and you must honor deletion and opt-out requests within one month.
- CCPA: If you’re targeting California-based contacts, CCPA requires transparency about how their data was sourced and a clear opt-out mechanism in your outreach.
Three rules that keep your team on solid ground are:
- Only scrape publicly available pages, never behind a login wall
- Only collect the data you need. Pulling more than necessary increases compliance risk without adding value to your outreach
- Respect robots.txt files and rate limits on the sites you scrape
Compliance is not something to bolt on after your pipeline is running. Build it in from the start.
When Web Scraping Makes Sense and When It Does Not
Web scraping is a strong fit for some targeting situations and a poor fit for others. Knowing the difference saves your team time and budget.
It works well when:
- Your target data is hyper-specific or niche and not available in any existing database
- You need real-time prospect data rather than a list compiled months ago
- You are targeting local or regional businesses where directories are the most reliable source
- You want buying signal data, like companies actively hiring for specific roles, that no vendor sells
It is less suited when:
- Your ICP is already well covered by a verified B2B data provider
- Your team does not have a process for cleaning and enriching scraped data before outreach
- You need to move fast and do not have time to validate a list before sending
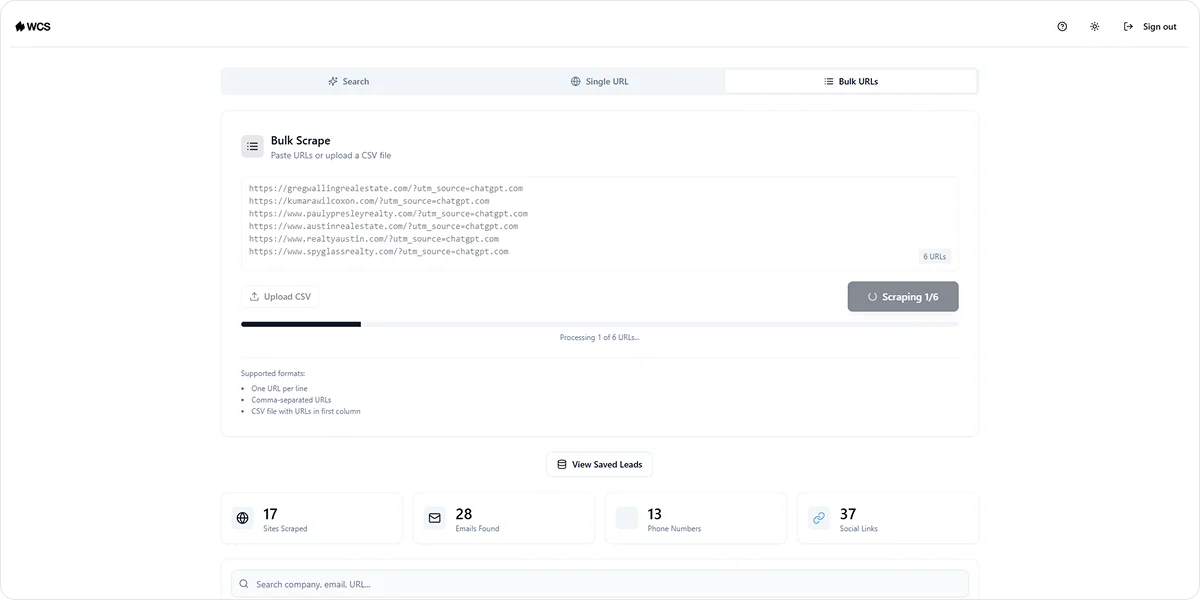
For teams that want the benefits of scraping without the cleanup work, a purpose-built tool that filters, structures, and exports the data directly removes most of that burden.
We Capture Sales's Market Miner handles exactly this, pulling contact data filtered by industry and location and delivering clean CSV exports your team can load into a CRM or outreach tool without additional processing.
How We Capture Sales Helps You Build a Stronger Lead Pipeline
Web scraping is one piece of a broader lead generation system. Getting the data is the first step. What your team does with it after, from outreach sequencing to pipeline management, determines whether it produces revenue.
We Capture Sales builds custom AI systems around how your business operates. Every engagement starts with a discovery conversation that maps your current pipeline, identifies where lead generation is breaking down, and determines what a practical build looks like before anything goes live.
Two products connect directly to the use cases covered in this article:
- Market Miner: Scrapes competitor activity and contact data filtered by industry and location, delivering clean CSV exports your team can act on without spending hours on manual research
- Pipeline Revival: Takes that contact data and runs targeted email and SMS sequences that adapt based on how each prospect responds, routing engaged contacts to a booking link or your website without manual handoff
Every client operates in a fully isolated AWS environment. The contact data your team collects through Market Miner stays private, is never shared, and never touches a public AI model.
If you are building a lead generation process from scratch or trying to figure out where your current one is breaking down, the discovery conversation is the right starting point. It is a one-on-one session focused entirely on your pipeline, your ICP, and what a practical scraping and outreach system looks like for your business specifically.
Reach out to the We Capture Sales team to schedule a meeting today.
Frequently Asked Questions
Is web scraping for lead generation legal?
Web scraping publicly available data is legal in the US following the hiQ vs LinkedIn ruling, but terms of service and privacy laws still apply. GDPR requires a documented lawful basis for processing personal data from EU contacts. CCPA requires transparency about data sourcing and an opt-out mechanism for California-based contacts. Building compliance into your process from the start is the safest approach.
How is web scraping different from buying a lead list?
A purchased list is compiled at a point in time and starts decaying immediately. Web scraping pulls data from live sources, so the contacts reflect what is published right now. It also gives your team a level of targeting specificity that purchased lists rarely offer, down to industry, location, company size, and active hiring signals.
What data can you collect through web scraping for B2B lead generation?
From publicly available sources, you can collect business names, job titles, work email addresses, phone numbers, company size, industry, location, and website URLs. Job boards add an extra layer of buying signal data, including hiring activity and tech stack mentions that help your team prioritize outreach.




